简单线性回归是一种统计方法,使我们能够总结和研究两个连续(定量)变量之间的关系。一个以x表示的变量被视为自变量,另一个以y表示的变量被视为因变量。假设这两个变量是线性相关的。因此,我们试图找到一个线性函数,尽可能准确地预测响应值(y)作为特征或自变量(x)的函数。
为了理解这个概念,让我们考虑一个薪水数据集,其中给定了每个自变量(经验年限)的因变量(薪水)的值。
薪资数据集
年薪和经验
1.1 39343.00
1.3 46205.00
1.5 37731.00
2.0 43525.00
2.2 39891.00
2.9 56642.00
3.0 60150.00
3.2 54445.00
3.2 64445.00
3.7 57189.00
出于一般目的,我们定义:
x作为特征向量,即x=[x_1,x_2,....,x_n],
y作为响应向量,即y=[y_1,y_2,....,y_n]
对于n次观察(在上面的示例中,n=10)。
给定数据集的散点图
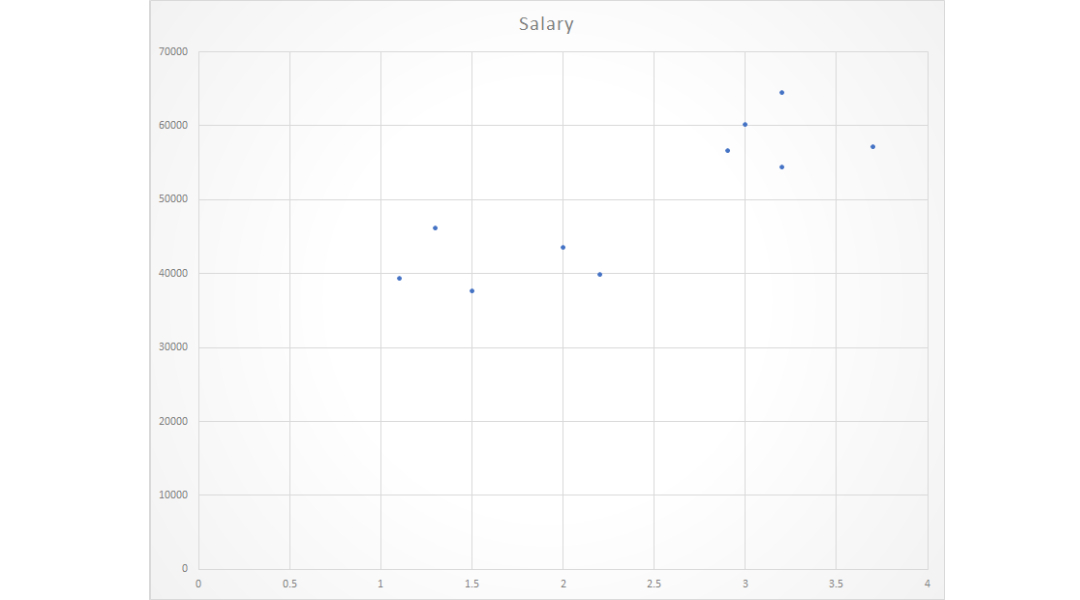
现在,我们必须找到一条适合上述散点图的线,通过它我们可以预测任何y值或任何x值的响应。
最适合的线称为回归线。
以下R代码用于实现简单线性回归
dataset=read.csv('salary.csv')
install.packages('caTools')
library(caTools)
split=sample.split(dataset$Salary,SplitRatio=0.7)
trainingset=subset(dataset,split==TRUE)
testset=subset(dataset,split==FALSE)
lm.r=lm(formula=Salary~YearsExperience,
data=trainingset)
coef(lm.r)
ypred=predict(lm.r,newdata=testset)
install.packages("ggplot2")
library(ggplot2)
ggplot()+geom_point(aes(x=trainingset$YearsExperience,
y=trainingset$Salary),colour='red')+
geom_line(aes(x=trainingset$YearsExperience,
y=predict(lm.r,newdata=trainingset)),colour='blue')+
ggtitle('Salary vs Experience(Training set)')+
xlab('Years of experience')+
ylab('Salary')
ggplot()+
geom_point(aes(x=testset$YearsExperience,y=testset$Salary),
colour='red')+
geom_line(aes(x=trainingset$YearsExperience,
y=predict(lm.r,newdata=trainingset)),
colour='blue')+
ggtitle('Salary vs Experience(Test set)')+
xlab('Years of experience')+
ylab('Salary')可视化训练集结果


