马尔可夫决策过程(MDP)是一种强化学习策略,用于将当前状态映射到代理不断与环境交互以产生新解决方案并获得奖励的动作。
马尔可夫过程(MDP)指出,在给定现在的情况下,未来独立于过去。这意味着,在给定当前状态的情况下,可以轻松预测下一个状态,而不需要先前的状态。
马尔可夫决策过程(MDP)使用该理论来获得我们机器学习模型中的下一个动作。
马尔可夫决策过程(MDP)使用:
- 一组状态(S)
- 一组模型
- 一组所有可能的动作(A)
- 取决于状态和动作R(S,A)的奖励函数
- 一种策略,它是MDP的解决方案
马尔可夫决策过程(MDP)的策略旨在最大化每个状态的奖励。代理与环境交互并在它处于一个状态时采取行动以达到下一个未来状态。我们的行动基于返回的最大奖励。
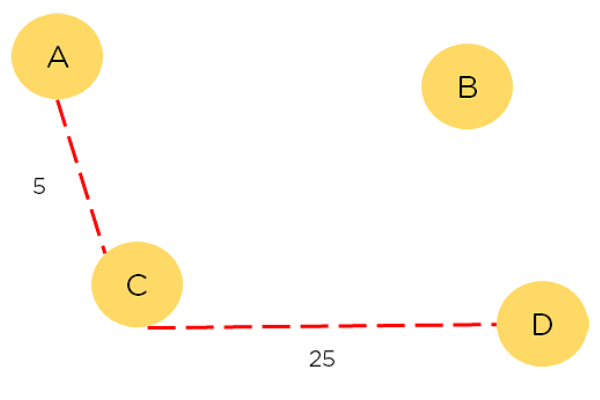
在下面所示的图表中,我们需要找到节点A和D之间的最短路径。每条路径都有与之关联的奖励,而奖励最大的路径就是我们想要选择的路径。节点;A B C D;表示节点。从一个节点到另一个节点(A到B)是一个动作。奖励是每条路径的成本,策略是采取的每条路径。
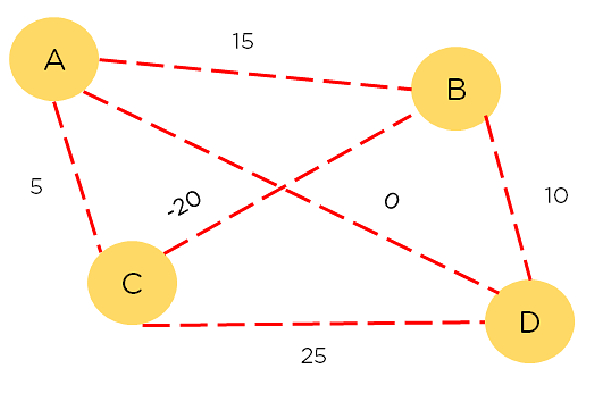
该过程将根据每一步的奖励最大化输出,并将遍历奖励最高的路径。这个过程不是探索而是最大化奖励。