随机森林算法是一种集成技术,能够使用多个决策树和一种称为Bootstrap和聚合的技术来执行回归和分类任务。这背后的基本思想是结合多个决策树来确定最终输出,而不是依赖于单个决策树。
机器学习中的随机森林
随机森林产生大量分类树。将输入向量放在森林中的每棵树下,以根据输入向量对新对象进行分类。每棵树都分配了一个分类,我们可以将其称为“投票”,最终选择最高票数的分类。
以下阶段将帮助我们了解随机森林算法的工作原理。
第1步:首先从数据集中选择随机样本。
第2步:对于每个样本,该算法将创建一个决策树。然后将获得每个决策树的预测结果。
第3步:将对这一步中的每个预期结果进行投票。
第4步:最后选择得票最多的预测结果作为最终的预测结果。
随机森林方法具有以下优点
- 通过平均或整合不同决策树的输出,它解决了过度拟合的问题。
- 对于范围广泛的数据项,随机森林比单个决策树表现更好。
- 即使缺少大量数据,随机森林算法也能保持高精度。
随机森林的特点
以下是随机森林算法的主要特征:
- 是目前可用的最准确的算法。
- 适用于庞大的数据库。
- 可以处理数以万计的输入变量,且不用删除其中任何一个变量。
- 随着森林的增长,它会生成泛化误差的内部无偏估计。
- 即使在大量数据丢失的情况下也能保持其准确性。
- 它包括用于平衡类人群中不均匀数据集的不准确性的方法。
- 创建的森林可以在将来保存并用于其他数据。
- 创建原型以显示变量和分类之间的关系。
- 它计算示例对之间的距离,这对于聚类、检测异常值或提供引人入胜的数据视图(按比例)很有用。
- 未标记的数据可用于使用上述功能创建无监督聚类、数据可视化和异常值识别。
随机森林有多个决策树作为基础学习模型。我们从数据集中随机执行行采样和特征采样,形成每个模型的样本数据集。这部分称为引导程序。
如何使用随机森林回归技术
- 设计一个特定的问题或数据并获取源以确定所需的数据。
- 确保数据是可访问的格式,否则将其转换为所需的格式。
- 指定获得所需数据可能需要的所有明显异常和缺失数据点。
- 创建机器学习模型。
- 设置想要实现的基线模型
- 训练数据机器学习模型。
- 使用测试数据提供对模型的洞察
- 现在比较测试数据和模型预测数据的性能指标。
- 如果它不能满足,可以尝试相应地改进模型或者使用其他数据建模技术。
- 在这个阶段,解释获得的数据并相应地报告。
Python实现随机森林算法流程
第1步:导入所需的库。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd第2步:导入并打印数据集
ata=pd.read_csv('Salaries.csv')
print(data)第3步:从数据集中选择所有行和第1列到x,选择所有行和第2列作为y
x=df.iloc[:,:-1]#”:”表示将选择所有行,“:-1”表示将忽略最后一列
y=df.iloc[:,-1:]#”:”表示它将选择所有行,“-1:”表示它将忽略除最后一列之外的所有列
#“iloc()”函数使我们能够选择数据集的特定单元格,也就是说,它帮助我们从数据框或数据集的一组值中选择属于特定行或列的值。
第4步:将随机森林回归器拟合到数据集
from sklearn.ensemble import RandomForestRegressor
regressor=RandomForestRegressor(n_estimators=100,random_state=0)
regressor.fit(x,y)第5步:预测新结果
Y_pred=regressor.predict(np.array([6.5]).reshape(1,1))第6步:可视化结果
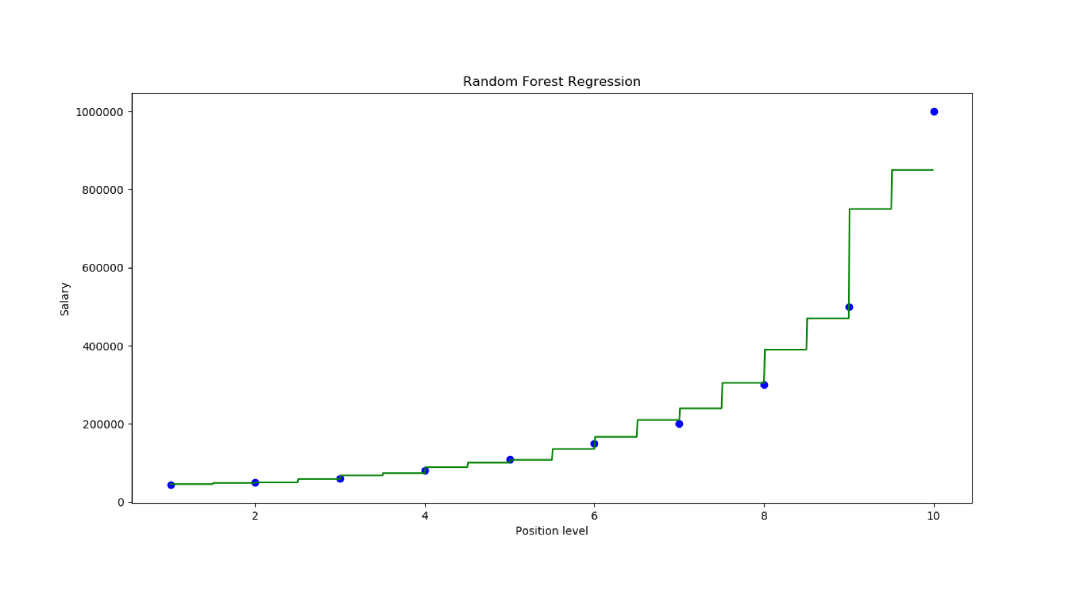
X_grid=np.arrange(min(x),max(x),0.01)
X_grid=X_grid.reshape((len(X_grid),1))
plt.scatter(x,y,color='blue')
plt.plot(X_grid,regressor.predict(X_grid),
color='green')
plt.title('Random Forest Regression')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
